In a world driven by technology, startups are the backbone of innovation. The excitement of building new applications, services, and products can be exhilarating, but it's crucial to ensure these creations can withstand the unpredictable challenges of the digital realm. Chaos Engineering is a concept that every startup owner and aspiring student developer should embrace to build robust and reliable applications from the ground up. In this article, we'll explore what Chaos Engineering is and why it's essential for the success of startups and the next generation of developers.
Understanding Chaos Engineering
Chaos Engineering is a discipline that seeks to uncover vulnerabilities in software systems by intentionally causing disruptions. These controlled experiments enable developers to identify weak points and bottlenecks before real-world issues occur. It's a proactive approach to building resilient systems, making it an invaluable tool for startups and students in their application development journey.
Chaos Injection: The Need of the Hour
Chaos Engineering is all about controlled chaos. By injecting controlled failures into your system, you can expose potential weaknesses, ensuring that your application can withstand the unpredictability of the digital landscape.
Here are some key chaos injections and why they are essential:
-
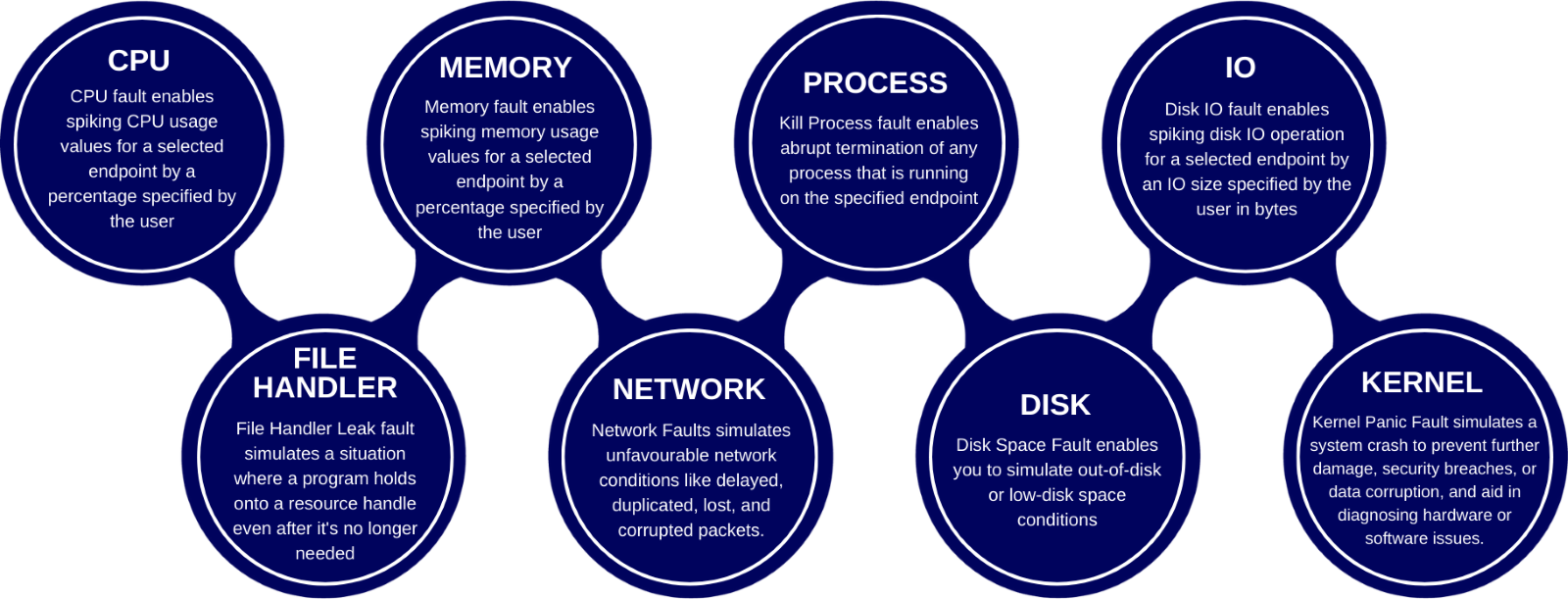
CPU Fault: This injection mimics spikes in CPU usage. In the real world, traffic spikes and increased loads can crash an application. Chaos Engineering helps you prepare for such scenarios, ensuring your system remains responsive.
Metrics
- CPU Usage: Measure the percentage of CPU utilization during the experiment.
- Load Average: Observe the system's load average, which provides insights into CPU and process utilization.
Memory Fault
An application consuming too much memory can slow down or crash. Memory faults allow you to simulate memory spikes, ensuring your application can handle these challenges effectively.
Metrics:
-
Memory Usage: Monitor the system's memory utilization, both physical and virtual.
-
Swap Usage: Track the usage of swap memory, which is particularly relevant when simulating memory spikes.
File Handler Leak
Resource management is critical. File handler leaks simulate situations where resources aren't released, helping you identify memory leaks and improve resource efficiency.
Metrics:
Network Faults: In the digital world, networks are never perfect. Simulating network issues like packet delays, duplication, loss, and corruption prepares your application to handle real-world network problems seamlessly.
Metrics:
-
Packet Loss: Measure the percentage of lost packets during the experiment to assess network fault tolerance.
-
Latency: Monitor network latency to see how network disruptions impact response times.
-
Throughput: Measure the network throughput to understand how data transfer rates are affected.
Process Termination: Sometimes, processes abruptly terminate. Chaos Engineering with kill process faults ensures your system can gracefully handle sudden process interruptions.
Metrics
Disk Space Fault: Running out of disk space can lead to catastrophic data loss. Simulating low disk space conditions prepares your application to manage storage efficiently.
Metrics:
-
Disk Space: Monitor disk space usage to simulate out-of-disk or low-disk conditions.
-
I/O Queue Length: Observe the disk I/O queue length to understand how it affects read/write operations.
-
Disk Latency: Measure the latency of disk operations during experiments.
Disk IO Fault: Spiking disk I/O operations test your system's ability to handle increased data demands. These tests ensure your application remains responsive during high data loads.
Metrics:
-
I/O Operations: Count the number of read and write operations per second.
-
I/O Size: Monitor the size of I/O operations (e.g., in bytes).
-
Disk Latency: Measure the latency of disk I/O operations.
Kernel Panic Fault: The operating system can experience sudden failures. Simulating a kernel panic helps diagnose and prevent severe hardware or software failures in your application.
Metrics:
-
System Errors: Record any system errors, such as kernel panics or abrupt system shutdowns.
-
Recovery Time: Measure the time it takes for the system to recover from kernel panic scenarios.
Why Chaos Engineering Matters
For startups, embracing Chaos Engineering is a forward-thinking approach to building applications. It helps identify weaknesses, enhance fault tolerance, and ensure business continuity. For students, learning about Chaos Engineering is a valuable skill that can set you apart in the competitive world of application development.
By intentionally breaking your system through chaos injections, you're in control. You find the cracks before your users do. The result? More robust, reliable, and scalable applications that can withstand the unpredictable nature of the digital landscape. So, whether you're a startup founder or an aspiring developer, remember that Chaos Engineering is your secret weapon for success. Embrace the chaos and build resilient applications that can thrive in a world of uncertainty.
Navigating Chaos: Tools and Strategies for Controlled Disruption
Chaos engineering platforms like Chaos Monkey (designed by Netflix), Gremlin, and LitmusChaos can help orchestrate these experiments in a more controlled and automated manner. However, for custom and fine-grained experiments, you may opt for specific tools and methods depending on your system's architecture and requirements.
Remember that the choice of tools and methods should align with your specific goals and the technologies your startup or project is using. Additionally, ensure proper monitoring and observability tools are in place to capture relevant metrics during chaos experiments.
About the Author
Mr. Thirukumaran Muthiah is a Chief Digital Officer at Dew Software Technologies. He is a visionary leader, entrepreneur, and philanthropist with over two decades of global experience. He has worked with Fortune 100 companies, including Tesla, PayPal, Citi, and Visa, creating innovative platforms and products. Thiru Kumaran is dedicated to transforming Madurai into a billion-dollar technology hub and has initiated projects to promote financial inclusion and environmental sustainability.